
Używasz Databricks Workspace i notebooków do analizy i przetwarzania danych, ale jeśli chodzi o złożone aplikacje, czy nie jest to już skuteczne podejście? Możesz połączyć się z klastrem Databricks z lokalnego IDE w celu uruchomienia kodu. Dowiedz się, jak to zrobić tutaj.
Wprowadzenie
Dzięki Databricks Workspace i notebookom jesteśmy w stanie szybko analizować i przekształcać dane. Jest to idealne rozwiązanie, o ile używamy go do zadań ad hoc lub nieskomplikowanych aplikacji. Jednak w przypadku bardziej złożonej pracy tworzenie kodu w przeglądarce w postaci notebooka jest wyczerpujące i nieskuteczne. Im dłuższy jest notatnik, tym trudniejszy jest do odczytania kodu, a środowisko i środowisko są mniej responsywne podczas próby użycia „autouzupełniania” lub dodawania komórek. Na szczęście jesteśmy w stanie pisać kod i uruchomić go bezpośrednio z lokalnego IDE. W tym artykule omówimy krok po kroku, jak połączyć się z klastrem databricks i uruchomić kod iskry za pomocą „złącza databricks”.
Wdrożenie
Zapewnij efektywność swojej pracy poprzez odpowiednie przygotowanie środowiska programistycznego, co jest niezbędne do pomyślnego łączenia się z klastrem Databricks z lokalnego IDE.
Przygotowanie środowiska
Aby połączyć się z klastrem w Databricks, wymagana jest odpowiednia wersja Pythona w środowisku programistycznym. Na przykład, jeśli łączysz się z klastrem za pomocą Databricks Runtime 7.3 LTS, musisz użyć Pythona w wersji 3.7. W tym momencie ważne jest, aby wspomnieć, że nie można połączyć się ze wszystkimi środowiskami wykonawczymi DB (ograniczenia zostaną opisane w dalszej części tego artykułu). Pełną listę obsługiwanych środowisk wykonawczych wraz z odpowiednimi wersjami Pythona można znaleźć tutaj.Kolejną ważną rzeczą jest zainstalowanie Java Runtime Environment 8 (JRE 8). Możesz użyć apt (Ubuntu/Debian distro), aby go zainstalować
Ponadto pakiet databricks-connect koliduje z PySpark. Więc jeśli twoje środowisko programistyczne py zawiera go, usuń go za pomocą poniższego kodu
Zdecydowanie sugeruje się również używanie czystego środowiska Pythona przy użyciu venv, conda lub innych. Takie podejście pozwoli Ci skonfigurować połączenia dla wielu klastrów/obszarów roboczych z jednego miejsca.
Połączenie z klastrem
Jak więc połączyć się z klastrem databricks? Gdy nasze środowisko lokalne będzie gotowe, możemy zainstalować pakiet databricks-connect. Wersja klienta powinna być taka sama jak Databricks Runtime. W naszym przypadku będzie to 7.3:
Należy pamiętać, że wersja klienta to „X.Y.*”, gdzie X.Y odpowiada Databricks Runtime (7.3), a przyrostek „.*” jest wersją pakietu. Używanie „*” gwarantuje, że zawsze używasz najnowszej wersji.
Po pomyślnym zakończeniu instalacji nadszedł czas, aby skonfigurować połączenie. Wcześniej musisz przygotować kilka rzeczy:
- Adres URL obszaru roboczego (host Databricks)
- Identyfikator klastra
- Identyfikator organizacji (Org ID) (tylko Azure!)
- Żeton osobisty
- Port przyłączeniowy
Pierwsze trzy parametry możemy znaleźć w adresie URL klastra, z którym chcemy się połączyć. W przeglądarce otwórz „Oblicz”, a następnie klaster, z którym chcesz się połączyć.

Możesz wygenerować osobisty token w „Ustawieniach użytkownika”. Możesz dowiedzieć się, jak to zdobyć tutajDomyślny port połączenia to 15001. Jeśli został zmieniony, prawdopodobnie znajdziesz go w „Opcjach zaawansowanych” w zakładce „Spark” (klucz konfiguracyjny „spark.databricks.service.port”) .Teraz, gdy wszystkie wymagane parametry są gotowe, możemy skonfigurować klienta połączenia databricks, uruchom:
Następnie podaj monitowane parametry. Następnie możesz sprawdzić połączenie:
Wyjście powinno wyglądać następująco:
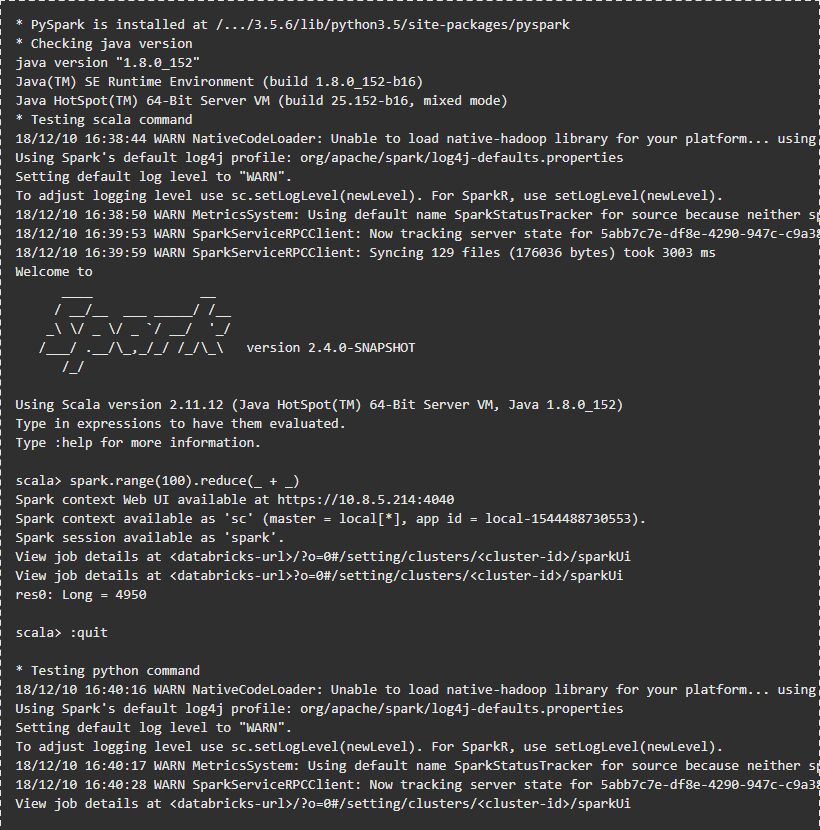
Uruchamianie przykładowego kodu
Integracja z VSC IDE
Przed uruchomieniem jakiegoś kodu w klastrze Databricks należy zintegrować łącznik databricks z IDE. W moim przypadku będzie to kod VisualVirtual Studio. Integracja złącza z VSC jest naprawdę łatwa, ponieważ wszystko, co musisz zrobić, to skierować IDE do środowiska Pythona, w którym zainstalowany jest łącznik databricks. Po uruchomieniu kodu PPYSpark złącze wykona go w klastrze DB.
Aby zmienić interpreter pythona w VSC, naciśnij klawisz F1 i zacznij pisać „Python: Select Interpreter”.

Następnie wybierz python env z listy lub podaj ścieżkę, w której umieszczony jest plik wykonywalny Python.
Teraz jesteś gotowy do uruchomienia kodu z IDE w klastrze DB. Złącze databricks rozpozna kod pyspark i uruchomi go na klastrze. Jeśli kod nie zawiera pyspark, wykonanie będzie odbywać się lokalnie. Poniżej znajduje się przykład kodu zawierającego fragment pyspark, który zostanie wykonany w klastrze DB
Zwróć uwagę, że najpierw należy utworzyć sesję iskry. Kiedy uruchamiamy jakiś kod bezpośrednio w obszarze roboczym databricks, sesja iskra jest już zainicjowana. Możesz znaleźć ten kod w tym magazyn.
Nie tylko VSC!
Możesz zintegrować planty IDE, np. PyCharm, Eclipse lub Jupyter Notebook. Możesz znaleźć instrukcje z konfiguracją innych IDE tutaj.
Dostęp do DButils
DButils to bardzo pomocny moduł, z którego można korzystać z notebooków. Z jego pomocą możesz czytać sekrety lub wykonywać polecenia FS na DBFS. Istnieje również możliwość korzystania z „dbutils” w taki sam sposób jak w notebookach databricks. Należy zainstalować jeszcze jedną bibliotekę i utworzyć obiekt dbutils. Aby wykonać to zadanie, zainstaluj pakiet „sześć” w swoim środowisku:
a teraz jesteśmy w stanie używać fs i tajemnic:
Możesz znaleźć ten przykład w magazyn.
Uzyskaj dostęp do kodu z obszaru roboczego DB
Możemy pobierać i przesyłać notatniki z obszaru roboczego DB za pomocą interfejsu wiersza polecenia databricks. Aby zainstalować interfejs wiersza polecenia, uruchom w terminalu:
Aby skonfigurować interfejs CLI databricks, potrzebujemy adresu URL obszaru roboczego i tokena. Opisałem powyżej, jak to zdobyć. Oba muszą zostać przekazane podczas konfiguracji:
Następnie należy użyć poleceń importu i eksportu:
Databricks CLI może być również używany do tworzenia klastrów, zarządzania dbfs itp. Możesz znaleźć pełną listę poleceń tutaj.
Nie tylko Py!
Możesz także skonfigurować środowisko i IDE, aby uruchamiać kod R i Scala! Więcej informacji można znaleźć w następujących linkach:
Ograniczenia
Niestety istnieją pewne ograniczenia dotyczące korzystania ze złącza databricks-connector. Przede wszystkim możemy używać tylko ograniczonych klastrów DB Runtime. W czasie pisania tego artykułu były to: 9.1 LTS, 7.3 LTS, 6.4 i 5.5 LTS. Jedynymi dostępnymi opcjami są moduły fs i secrets od dbutils. Moduły biblioteki, notebooków lub widżetów nie są obsługiwane w łączniku databricks-connector. Co więcej, nie ma możliwości łączenia się z klastrami za pomocą kontroli dostępu do tabeli. Są to najbardziej wpływowe ograniczenia. Pełną listę można znaleźć w następujących linkach:
Podsumowanie
Jak widać, skonfigurowanie pakietu „databricks connect” jest proste i znacznie przyspiesza rozwój przy użyciu ulubionego IDE. Cały potrzebny kod można znaleźć w specjalnie stworzonym GitHubie magazyn. Sprawdź nasz blog, aby dowiedzieć się więcej o klastrach Databricks. Sprawdź nasz blog, aby uzyskać bardziej szczegółowe artykuły na temat Databricks:
- Przechwytywanie skróconych wyjść komórek Databricks
- Wprowadzenie do koali i databricks
- Testowanie Databricks z działaniami GitHub




