
Obecnie aplikacje stają się coraz bardziej złożone i składają się z coraz większej liczby technologii. Monitorowanie ich może być twardym orzechem do pękania, szczególnie w chmurze. Nawet w przypadku dość prostej hurtowni danych z rurociągami ETL/ELT powinieneś być w stanie monitorować bazę danych, orkiestrator, silnik przetwarzania itp. Na szczęście platforma GCP ma dobrą usługę monitorowania i alarmowania. W tym samouczku została utworzona funkcja chmury HTTP

Rejestracja GCP
Monitorowanie nie może odbywać się bez odpowiedniego rejestrowania. GCP zapewnia dobrą jakość dzienników dla usług GCP i umożliwia dodawanie własnych dzienników aplikacji, np. logów python w przetwarzaniu funkcji w chmurze. Można je łatwo przeszukiwać za pomocą ładnego interfejsu użytkownika (UI):

Dzienniki aplikacji są niezwykle ważne dla debugowania i tworzenia metryk opartych na dziennikach, które później mogą być używane do monitorowania naszego środowiska GCP.
Metryki
GCP zapewnia ogromną liczbę metryk do monitorowania po wyjęciu z pudełka, w tym zarówno usługi natywne, takie jak BigQuery, Cloud Function, Composer itp., jak i usługi takie jak AWS, Kubernetes. Wystarczy spojrzeć na wykresy z egzekucjami CF.

Istnieje również sposób tworzenia własnych metryk opartych na dziennikach, które będą później wykorzystywane do monitorowania i alarmowania. Monitorowanie metryk z wielu projektów jest również dostępne za pomocą projektów zakresowania.
Metryki oparte na dzienniku
Dzienniki mogą być używane do tworzenia liczników, dystrybucji lub metryk logicznych. Na początku najbardziej przydatne mogą być dwa pierwsze, które można wykorzystać do:
- policzyć liczbę dzienników spełniających określony warunek lub dystrybucję, np. liczbę rozpoczętych zadań
- śledzenie czasu wykonania zadania i jego historycznych rozkładów
Tworzenie metryk umożliwia również dodawanie etykiet do metryk, jednak należy je używać ostrożnie, ponieważ pamięć masowa może szybko rosnąć, a także koszt. Poniżej znajdziesz przykładowy opis log-based metric accounting komunikatów (błędy) śledzenia funkcji Cloud Function.Rzeczy warte uwagi:
- metryki nie mogą być obliczane dla dzienników historycznych
- nowe metryki są widoczne od razu w eksploratorze metryk, ale mogą być nieaktywne przez pewien czas, dopóki nie zostaną przetworzone nowe dzienniki spełniające warunki metryczne

Monitorowanie za pomocą GCP
GCP umożliwia monitorowanie aplikacji na wiele sposobów za pomocą usług monitorowania w chmurze lub raportowania błędów. Są niezwykle przydatne i mogą być używane osobno w zależności od przypadku użycia.
Monitorowanie chmury
Monitoring w chmurze umożliwia zbieranie i monitorowanie metryk GCP, które później można przeglądać za pomocą pulpitów nawigacyjnych. Metryki mogą być analizowane osobno, w grupach lub nawet dla usług za pomocą zdefiniowanego SLO (Service Level Objective). Usługi można dodawać ręcznie, jeśli nie zostaną wykryte automatycznie.
Pulpity nawigacyjne
Pierwszy poziom analizy metrycznej można zaobserwować za pomocą wizualizacji pulpitów nawigacyjnych. Wiele typów wykresów pomoże Ci monitorować ogólny stan środowiska i aplikacji. Przykładowy wykres wykorzystujący utworzoną metrykę opartą na logach można znaleźć poniżej:

Alerty GCP
Alerty GCP to potężna funkcja, która pomaga proaktywnie monitorować aplikacje i systemy poprzez konfigurowanie zasad ostrzegania. Zasady te powiadamiają użytkownika o spełnieniu określonych warunków, takich jak nietypowe wartości metryczne lub brakujące wskaźniki, zapewniając możliwość rozwiązania problemów przed ich eskalacją.
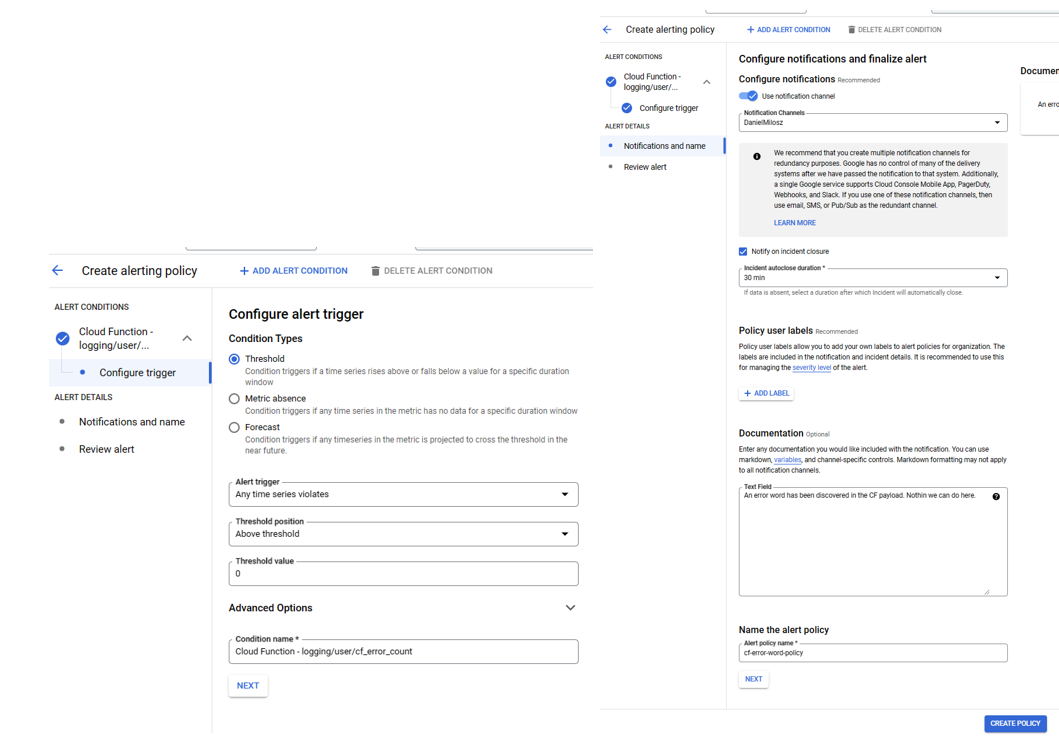
Pulpity nawigacyjne są niezwykle przydatnymi narzędziami do codziennego monitorowania aplikacji, jednak nie informują Cię o nagłych awariach — w tym celu konieczne będzie ostrzeżenie. Zasady ostrzegania można skonfigurować w celu wywołania alertu w przypadku spełnienia pewnych warunków, np. metryki wskazują na coś niepokojącego w systemie lub w ogóle brakuje metryki przez kilka minut. Wywołanie alertu tworzy bilet, którym należy zarządzać, a także może wysyłać powiadomienie do interesariuszy za pośrednictwem wielu kanałów, takich jak slack lub e-mail. Bilet zawiera informacje o tym, co poszło nie tak i możliwość szybkiego nawigacji do powiązanych metryk/dzienników. Tworzenie polityki alertów można wykonać w zaledwie kilku krokach.Najpierw musisz opisać metrykę, którą chcesz monitorować:

Następnie należy podać informacje o wyzwalaczu i metodzie powiadamiania.
Po utworzeniu, gdy wystąpi problem, otrzymasz wiadomość e-mail jak poniżej.

Możesz także przejść do alerty/incydentów i łatwo przejść do odpowiednich dzienników związanych z problemem:

Sprawdzanie czasu pracy
Sprawdzanie czasu pracy to kolejny łatwy sposób monitorowania aplikacji. Dzięki niemu możesz zweryfikować dostępność swojej usługi. Nawet prywatne adresy IP i/lub usługi mogą być monitorowane, jednak istnieją pewne ograniczenia. W najgorszym przypadku sprawdzenie brakujących wskaźników można skonfigurować w celu wywołania alarmu. W poniższym przykładzie weryfikujemy stronę internetową naszej firmy.

Jak widać po kilku minutach wszystkie kontrole przechodzą

Raportowanie błędów GCP
Raportowanie błędów GCP umożliwia monitorowanie środowiska pod kątem błędów, które są automatycznie agregowane w grupy w celu łatwiejszego zarządzania. Ta funkcja pomaga szybko zidentyfikować nowe typy błędów i podejmować działania w razie potrzeby.
GCP umożliwia również monitorowanie środowiska pod kątem błędów, które później są agregowane w grupy. Pozwala to łatwo odkrywać nowe rodzaje błędów i reagować w razie potrzeby.

Warto zauważyć, że interfejs użytkownika jest przyjazny dla użytkownika i możesz przejść do dzienników aplikacji za pomocą zaledwie kilku kliknięć. Poniższy rysunek pokazuje szczegółowe informacje o grupie błędów:

Warto wspomnieć, że aby usługa wykrywała błędy aplikacji, dzienniki muszą zawierać ślad stosu lub być obiektem ReporteDerOrEvent.
Przyszłość inżynierii danych - trendy do obserwacji w 2025 roku
Jaka jest wiarygodność danych? Definicja i przykłady
Rozwój testowy w Pythonie przy użyciu Pytest




