
Przechwytywanie skróconych wyjść komórek Databricks
Kiedy uruchamiamy komórkę Capture Databricks w środowisku Azure, zwykle otrzymujemy pewne dane wyjściowe z komórki. Może wyglądać tak:
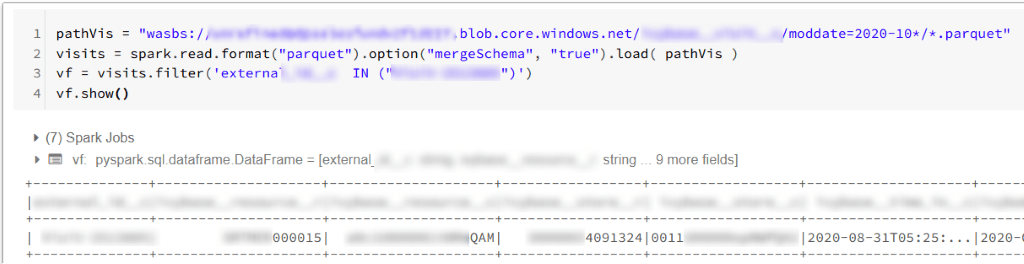
Najczęściej nie napotkamy problemu z takim podejściem. Niestety zdarzają się przypadki, kiedy Capture Databricks usunie niektóre części wyjścia. Stanie się tak, gdy nasz skrypt wygeneruje setki linii na wyjściu. Jeśli rozmiar tak długiego wyjścia przekroczy próg Databricks (szacowany limit: 128 kB), notebook powróci skracona moc wyjściowa. Gdy dane wyjściowe nie zawierają ważnych informacji - możemy się z tym pogodzić. Innym razem - być może będziemy musieli wyodrębnić cenne informacje z wyjścia, a skrócenie zrujnuje efekty naszego skryptu lub uniemożliwi nam poznanie rzeczywistego wyniku notebooka.
W naszym przypadku napotkaliśmy ten problem podczas wykonywania dużych zadań połykania łączących się z API Planorama i Salesforce API. Poniżej możemy zobaczyć przykład skróconego wyjścia:
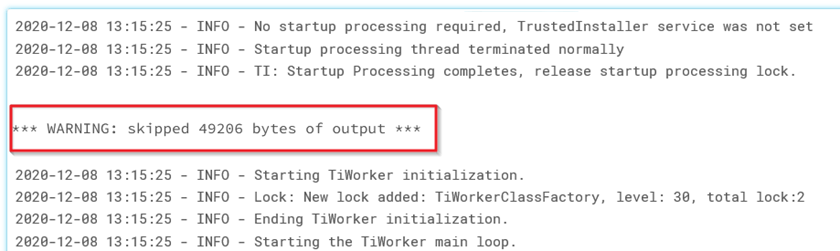
Nasze wyniki zwracały setki linii wyjściowych, ale tylko kilka linii miało znaczenie. Chcieliśmy wyodrębnić trzy informacje: kod kraju, dzień, i rozmiar pobierania Dla tego kraju i dnia. Poniżej znajduje się przykład wyników zawierających te informacje:

Rozwiązaniem problemu skróconego wyjścia jest umieszczenie gdzieś w naszym skrypcie fragmentów kodu dla:
- przechwytywanie wszystkich danych wyjściowych,
- analizowanie tego wyjścia i przechowywanie na bok informacji, których potrzebujemy
- Wreszcie wyświetla raport HTML.
Używanie HTML do raportu jest cennym hackiem, zapewniającym nam dodatkową metodę wyświetlania informacji pod komórką, która nie zostanie skrócona przez przechwytywanie Databricks.
Potrzebujesz pomocy z Capture Databricks? Sprawdź nasze Usługi inżynierii danych i zobacz, jak możemy pomóc Twojemu biznesowi
Jak zhakować problem z przyciętymi wyjściami za pomocą HTML:3-etapowy proces przechwytywania wyjść Databricks
Obsługa przyciętych wyjść w Databricks może być trudne, zwłaszcza w przypadku dużych prac związanych z połykaniem. Aby skutecznie przechwytywanie Databricks wyjścia i uniknięcie utraty cennych informacji, możesz postępować zgodnie z tym 3-etapowym procesem:
1. Przechwytywanie wyjścia
Pierwszą rzeczą, którą musimy zrobić, jest umieszczenie poniższego kodu, gdzieś przed uruchomieniem głównego skryptu:
z IPython.utils.Capture import CaptureDioprzechwytywanie = CaptureDio (sys.stdout, sys.stderr)
Spowoduje to przygotowanie zmiennej Captura Databricks (z nieruchomością stdout), który będzie zawierał dane wyjściowe komórki. Później możemy odwołać się do właściwości tej zmiennej, gdy chcemy sprawdzić bieżące wyjście.
Przygotowujemy również dodatkową listę do przechowywania danych wyjściowych podczas postępu spożycia:
Całe wyjście = []
2. Analizowanie danych wyjściowych i przechowywanie informacji w celu przechwytywania wyjść Databricks
W tym kroku, używając wyżej wymienionej zmiennej przechwytywa.stdout, możemy przechwytywanie Databricks wyjścia i wyodrębnianie znaczących informacji. Pozwala nam to analizować dane wyjściowe i przechowywać tylko odpowiednie dane do dalszego wykorzystania.
Na przykład w naszym przypadku użyliśmy następującego skryptu (kluczowe zmienne zostały wyróżnione), aby wyodrębnić kluczowe szczegóły, takie jak kody krajów, daty i rozmiary pobierania. Skrypt został wstrzyknięty do pętli połknięcia, umożliwiając nam przedłużenie Całe wyjście lista z przeanalizowanymi danymi:
defi uproszczony dziennik (dziennik): return [i dla i w log.splitlines (), jeśli 'Pobrane' w i\ lub „Rozpoczęcie spożycia” w i]# przeglądaj OUTPUT i uzyskaj rozmiary pobierania raportu: klucz, raport = „, {}Całe wyjście.extension (uproszczony_dziennik (przechwytywa.stdout))dla l in Całe wyjście: l = re.sub (r„.*? \ +\ +Początek połknięcia: „, „*”, l) # wyodrębnij kod kraju (1:3) i datę (4:14) jeśli l.startswith ('*'): klucz = l [1:3] + '-' + l [4:14] jeśli „INFO - pobrano:” w l: # wyciąć ciąg, usuwając tylko rozmiar pobierania l = re.sub (r„.*? root - INFO - Pobrano: (.*)”, r„\ 1", l) report [key] = l.strip () # przechowuje tylko rozmiar pobierania
3. Wyświetlanie raportu
Ostatnim etapem jest pokazanie raportu HTML - jak wspomniano wcześniej - ta metoda jest niezależną formą wyprowadzania informacji pod pojedynczą komórką, a Databricks obcinający dane wyjściowe nie zakłóci naszego raportu.
Nasz projekt wykorzystał poniższą prostą funkcję wyświetlania raportu:
def ShowReport (self): html = ["'<DOCTYPE HTML><BODY> <h2>Połknięcie zakończ</h2> <p>one KRAJ: <b>{}</b></p> <table><tr><th>Data pobrania</th> <th>„</th></tr>'.format\ („, „.join (self.country) .upper ())] dla klucza na liście (self.report.keys ()) .sort (): rozmiar = self.report [klucz] html.append (” <tr><td>"+ klucz + '' +</td> <td>rozmiar +</td>" „) html.append (” „)</table></BODY></HTML> displayHTML (”\ n „.join ([x dla x w html, jeśli wpisz (x)! = typ (typ)]))
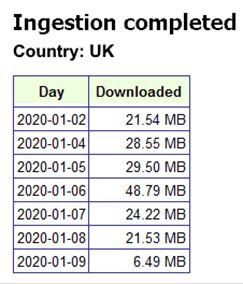
Powyższa metoda tworzy raport, który jest pokazany na końcu każdy iteracja pętli - daje nam częste informacje zwrotne na temat postępów połykania:
Odwiedź nasz blog, aby uzyskać bardziej szczegółowe artykuły dotyczące inżynierii danych:




