
Heutzutage werden Anwendungen immer komplexer und bestehen aus einer zunehmenden Anzahl von Technologien. Ihre Überwachung kann eine harte Nuss sein, insbesondere in der Cloud. Selbst für ein recht einfaches Data Warehouse mit ETL/ELT-Pipelines sollten Sie in der Lage sein, Datenbank, Orchestrator, Verarbeitungsengine usw. zu überwachen. Zum Glück bietet die GCP-Plattform einen guten Überwachungs- und Warndienst. Zu diesem Tutorial wurde die HTTP-Cloud-Funktion erstellt

GCP-Protokollierung
Ohne eine ordnungsgemäße Protokollierung kann keine Überwachung durchgeführt werden. GCP bietet Ihnen eine gute Qualität der Protokolle für die GCP-Dienste und ermöglicht es Ihnen, Ihre eigenen Anwendungsprotokolle hinzuzufügen, z. B. Python-Protokolle in die Cloud-Funktionsverarbeitung. Sie können einfach über eine schöne Benutzeroberfläche (UI) durchsucht werden:

Anwendungsprotokolle sind äußerst wichtig für das Debugging und die Erstellung protokollbasierter Metriken, die später zur Überwachung unserer GCP-Umgebung verwendet werden können.
Metriken
GCP bietet eine Vielzahl von Metriken, die sofort überwacht werden können, darunter sowohl native Dienste wie BigQuery, Cloud Function, Composer usw. als auch Dienste wie AWS, Kubernetes. Schauen Sie sich einfach die Diagramme mit CF-Ausführungen an.

Es gibt auch eine Möglichkeit, unsere eigenen Metriken auf der Grundlage von Protokollen zu erstellen, die später für die Überwachung und Alarmierung verwendet werden. Mithilfe von Bereichsprojekten können auch Kennzahlen aus mehreren Projekten überwacht werden.
Logbasierte Metriken
Logs können verwendet werden, um Zähler, Verteilungen oder boolesche Metriken zu erstellen. Am Anfang können die ersten beiden am nützlichsten sein. Sie können verwendet werden, um:
- Zählen Sie die Anzahl der Protokolle, die eine bestimmte Bedingung oder Verteilung erfüllen, z. B. die Anzahl der gestarteten Jobs
- Verfolgen Sie die Ausführungszeit von Jobs und ihre historischen Verteilungen
Das Erstellen von Metriken ermöglicht auch das Hinzufügen von Labels zu Metriken. Dabei muss jedoch vorsichtig vorgegangen werden, da der Speicher schnell wachsen kann und damit auch die Kosten steigen. Im Folgenden finden Sie ein Beispiel für eine protokollbasierte Metrik, die Traceback-Meldungen (Fehler) von Cloud-Funktionen zählt. Dinge, die es zu beachten gilt:
- Metriken können für historische Logs nicht berechnet werden
- neue Metriken sind sofort im Metrik-Explorer sichtbar, aber sie können für einige Zeit inaktiv sein, bis neue Logs, die die Metrikbedingungen erfüllen, verarbeitet werden

Überwachung mit GCP
GCP ermöglicht es Ihnen, Ihre Anwendung auf verschiedene Arten zu überwachen, indem Sie Cloud Monitoring- oder Error Reporting-Dienste verwenden. Sie sind äußerst nützlich und können je nach Anwendungsfall separat verwendet werden.
Cloud-Überwachung
Cloud Monitoring ermöglicht das Sammeln und Überwachen von GCP-Metriken, die später über Dashboards eingesehen werden können. Die Metriken können separat, in Gruppen oder sogar für Dienste anhand eines definierten SLO (Service Level Objective) analysiert werden. Die Dienste können manuell hinzugefügt werden, wenn sie nicht automatisch erkannt werden.
Dashboards
Die erste Ebene der Metrikanalyse kann anhand von Dashboard-Visualisierungen beobachtet werden. Verschiedene Arten von Diagrammen helfen Ihnen dabei, den Gesamtstatus Ihrer Umgebung und Ihrer Anwendungen zu überwachen. Ein Beispieldiagramm, das eine erstellte logbasierte Metrik verwendet, finden Sie unten:

GCP-Warnmeldungen
GCP-Warnmeldungen ist eine leistungsstarke Funktion, mit der Sie Ihre Anwendungen und Systeme proaktiv überwachen können, indem Sie Warnrichtlinien einrichten. Diese Richtlinien benachrichtigen Sie, wenn bestimmte Bedingungen erfüllt sind, z. B. ungewöhnliche Messwerte oder fehlende Metriken. So stellen Sie sicher, dass Sie Probleme beheben können, bevor sie eskalieren.
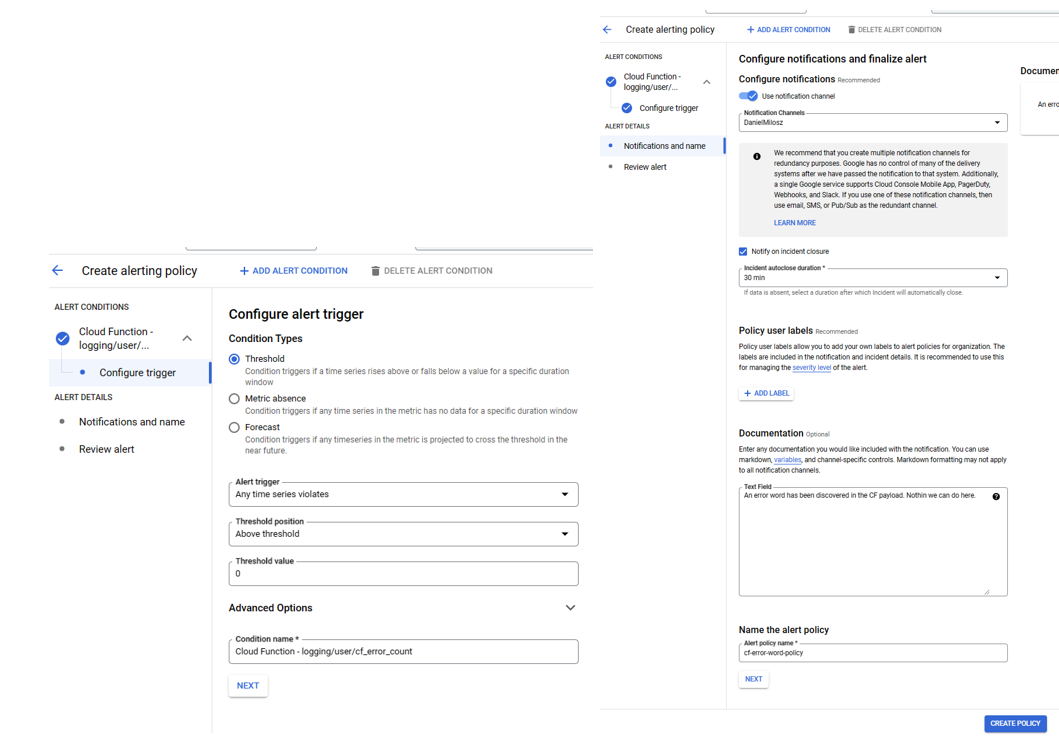
Dashboards sind äußerst nützliche Tools für die tägliche Überwachung Ihrer Anwendung. Sie werden jedoch nicht über plötzliche Ausfälle informiert — zu diesem Zweck sind Warnmeldungen erforderlich. Eine Warnrichtlinie kann eingerichtet werden, um eine Warnung auszulösen, falls bestimmte Bedingungen erfüllt sind, z. B. wenn die Messwerte auf etwas Beunruhigendes am System hinweisen oder die Metrik einige Minuten lang überhaupt nicht vorhanden ist. Das Auslösen einer Warnung erzeugt ein Ticket, das verwaltet werden muss. Außerdem kann eine Benachrichtigung über mehrere Kanäle wie Slack oder E-Mail an die Beteiligten gesendet werden. Das Ticket enthält Informationen darüber, was schief gelaufen ist, und bietet die Möglichkeit, schnell zu entsprechenden Metriken/Protokollen zu navigieren. Das Erstellen einer Warnrichtlinie kann in nur wenigen Schritten erfolgen. Zuerst müssen Sie die Metrik beschreiben, die Sie überwachen möchten:

Anschließend müssen die Informationen über den Auslöser und die Benachrichtigungsmethode bereitgestellt werden.
Nach der Erstellung erhalten Sie bei Problemen eine E-Mail wie unten beschrieben.

Sie können auch zu Alarmen/Vorfällen gehen und einfach zu den richtigen Protokollen navigieren, die mit dem Problem verbunden sind:

Verfügbarkeitsüberprüfungen
Uptime Check ist eine weitere einfache Methode zur Anwendungsüberwachung. Dank dieser Funktion können Sie die Verfügbarkeit Ihrer Dienste überprüfen. Sogar private IPs und/oder Dienste können überwacht werden, es gibt jedoch einige Einschränkungen. Im schlimmsten Fall kann die Überprüfung fehlender Metriken so eingerichtet werden, dass eine Warnung ausgelöst wird. Im folgenden Beispiel verifizieren wir unsere Unternehmenswebseite.

Wie Sie vielleicht sehen, sind nach ein paar Minuten alle Prüfungen bestanden.

GCP-Fehlerberichterstattung
GCP-Fehlerberichterstattung ermöglicht es Ihnen, Ihre Umgebung auf Fehler zu überwachen, die zur einfacheren Verwaltung automatisch in Gruppen zusammengefasst werden. Mit dieser Funktion können Sie neue Arten von Fehlern schnell identifizieren und bei Bedarf Maßnahmen ergreifen.
GCP ermöglicht es Ihnen auch, Ihre Umgebung auf Fehler zu überwachen, die später in Gruppen zusammengefasst werden. Auf diese Weise können Sie ganz einfach neue Arten von Fehlern entdecken und bei Bedarf reagieren.

Es ist erwähnenswert, dass die Benutzeroberfläche benutzerfreundlich ist und Sie mit nur wenigen Klicks in die Anwendungsprotokolle wechseln können. Das folgende Bild zeigt detaillierte Informationen zur Fehlergruppe:

Es ist erwähnenswert, dass die Protokolle Stack-Trace enthalten oder das ReportedErrorEvent-Objekt sein müssen, damit der Dienst Anwendungsfehler erkennen kann.
Die Zukunft der Datentechnik — Trends, die es 2025 zu beobachten gilt
Wie hoch ist die Zuverlässigkeit von Daten? Definition und Beispiele
Testgetriebene Entwicklung in Python mit Pytest




