
Die verkürzten Ausgaben der Zellen von Databricks erfassen
Wenn wir eine Capture Databricks-Zelle in der Azure-Umgebung ausführen, erhalten wir normalerweise eine Ausgabe von der Zelle. Das kann so aussehen:
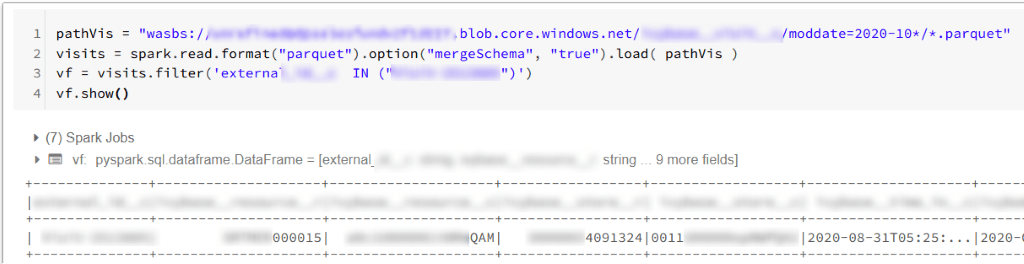
In den meisten Fällen werden wir mit einem solchen Ansatz nicht auf ein Problem stoßen. Leider gibt es Fälle, in denen Capture Databricks einige Teile der Ausgabe entfernt. Es wird passieren, wenn unser Skript Hunderte von Zeilen in der Ausgabe generiert. Wenn eine so lange Ausgabe den Schwellenwert von Databricks überschreitet (geschätzte Grenze: 128 kB), kehrt das Notebook zurück gekürzte Ausgabe. Wenn die Ausgabe keine wichtigen Informationen enthält, könnten wir damit einverstanden sein. In anderen Fällen müssen wir möglicherweise einige wertvolle Informationen aus der Ausgabe extrahieren, und die Kürzung ruiniert die Auswirkungen unseres Skripts oder verhindert, dass wir die tatsächliche Ausgabe des Notizbuchs kennen.
In unserem Fall sind wir auf dieses Problem gestoßen, als wir große Aufnahmeaufträge ausführen, die eine Verbindung zur Planorama-API und zur Salesforce-API herstellen. Unten sehen wir ein Beispiel für eine verkürzte Ausgabe:
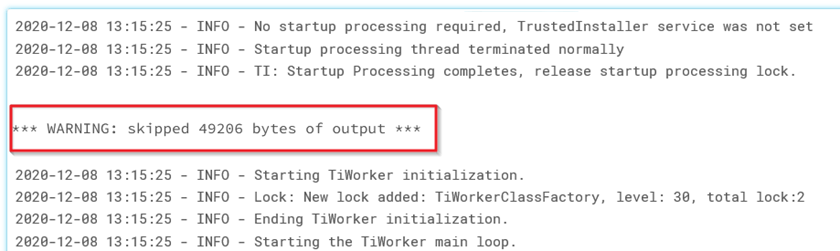
Unsere Ausgabe gab Hunderte von Ausgabezeilen zurück, aber nur wenige Zeilen waren aussagekräftig. Wir wollten drei Informationen extrahieren: Landesvorwahl, Tag, und Größe herunterladen für dieses Land und diesen Tag. Unten finden Sie ein Beispiel für die Ausgabe, die diese Informationen enthält:

Die Lösung für das Problem der verkürzten Ausgabe besteht darin, irgendwo in unserem Skript einen Codeausschnitt zu platzieren für:
- Abfangen der gesamten Ausgabe,
- diese Ausgabe analysieren und die Informationen, die wir benötigen, beiseite speichern
- zeigt endlich einen HTML-Bericht.
Die Verwendung des HTML-Codes für einen Bericht ist ein wertvoller Hack, der uns eine zusätzliche Methode bietet, Informationen unter einer Zelle anzuzeigen, die nicht von Capture Databricks gekürzt werden.
Benötigen Sie Hilfe mit Capture Databricks? Schauen Sie sich unsere an Dienstleistungen im Bereich Datentechnik und sehen Sie, wie wir Ihrem Unternehmen helfen können
So hacken Sie ein Problem mit abgeschnittenen Ausgaben mit HTML: 3-stufiger Prozess zum Erfassen von Databricks-Ausgaben
Behandlung abgeschnittener Ausgaben in Datenbausteine kann eine Herausforderung sein, insbesondere wenn es um Arbeiten mit großen Mengen an Nahrungsmitteln geht. Zu effektiv Databricks erfassen Ausgaben und um den Verlust wertvoller Informationen zu vermeiden, können Sie diesem 3-stufigen Prozess folgen:
1. Die Ausgabe abfangen
Das erste, was wir tun müssen, ist den folgenden Code irgendwo vor dem Start des Hauptskripts zu platzieren:
aus ipython.utils.Capture importiere CaptureDIOerfassen = captureDIO (sys.stdout, sys.stderr)
das bereitet eine Variable C vorErfassen Sie Databricks (mit einer Immobilie stdout), das die Ausgabe der Zelle enthalten wird. Später können wir auf die Eigenschaften dieser Variablen zurückgreifen, wann immer wir die aktuelle Ausgabe überprüfen wollen.
Wir bereiten auch eine zusätzliche Liste für die Speicherung der Ausgabe während der Aufnahme vor:
Ganze Ausgabe = []
2. Analysieren der Ausgabe und Speichern der Informationen in den Ausgaben von Capture Databricks
In diesem Schritt verwenden Sie die oben genannte Variable capture.stdout, wir können Databricks erfassen gibt aussagekräftige Informationen aus und extrahiert sie. Dadurch können wir die Ausgabe analysieren und nur die relevanten Daten für die weitere Verwendung speichern.
In unserem Fall haben wir beispielsweise das folgende Skript verwendet (wichtige Variablen wurden hervorgehoben), um wichtige Details wie Ländercodes, Daten und Download-Größen zu extrahieren. Das Skript wurde in die Aufnahmeschleife eingefügt, sodass wir die Erweiterung des Gesamter Output Liste mit den analysierten Daten:
def simplified_log (Protokoll): gib [i] für i in log.splitlines () zurück, wenn in i 'Heruntergeladen' oder „Beginn der Aufnahme“ in [i]# durchsuche das OUTPUT und finde die Download-Größen für den Bericht heraus: Schlüssel, Bericht = „, {}Gesamter Output.extend (vereinfachtes_log ())capture.stdout))für l in Gesamter Output: l = re.sub (r„.*? \ +\ +Beginn der Aufnahme: „, „*“, l) # extrahiere CountryCode (1:3) und Datum (4:14) wenn l.startswith ('*'): key = l [1:3] + '-' + l [4:14] wenn „INFO — Heruntergeladen:“ in l: # schneide die Zeichenfolge ab und entferne nur die Download-Größe l = re.sub (r„.*? root - INFO - Heruntergeladen: (.*)“, r„\ 1", l) report [key] = l.strip () # Nur die Download-Größe speichern
3. Den Bericht anzeigen
In der letzten Phase wird der HTML-Bericht angezeigt — wie bereits erwähnt — bei dieser Methode handelt es sich um eine unabhängige Form der Ausgabe der Informationen unter einer einzelnen Zelle. Wenn Databricks die Ausgabe kürzen, wird unser Bericht nicht manipuliert.
Unser Projekt verwendete die folgende, einfache Funktion zum Anzeigen des Berichts:
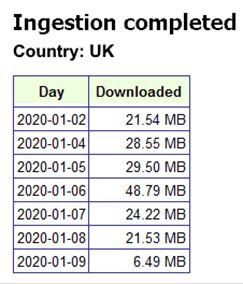
def showReport (self): html = ["'<DOCTYPE HTML><BODY> <h2>Aufnahme abgeschlossen</h2> <b><p>LAND: {}</p></b> <table><tr><th>Datum des</th> <th>Herunterladens</th></tr> „'.format\ („, „.join (self.countries) .upper ())] für Schlüssel in list (self.report.keys ()) .sort (): size = self.report [Schlüssel] html.append (“ <tr><td>"+ Schlüssel + '' +</td> <td>Größe +</td>" „) html.anhängen (“ „)</table></BODY></HTML> DisplayHtml (“\n„.join ([x) für x in HTML, wenn Sie (x) eingeben! = Typ (Typ)]))
Die obige Methode erzeugt den Bericht, der am Ende von angezeigt wird jeder Loop-Iteration — gibt uns regelmäßig Feedback zum Fortschritt der Einnahme:
Besuchen Sie unseren Blog für ausführlichere Data Engineering-Artikel:




