
Du nutzt Databricks Workspace und Notebooks zur Analyse und Verarbeitung von Daten, aber ist dieses Vorgehen bei komplexeren Anwendungen noch effektiv? Du kannst dich von deiner lokalen IDE mit einem Databricks Cluster verbinden, um deinen Code auszuführen. Erfahre hier, wie das geht.
Einleitung
Dank Databricks Workspace und Notebooks können wir Daten schnell analysieren und transformieren. Das ist eine perfekte Lösung für Ad-hoc-Aufgaben oder nicht zu komplexe Anwendungen. Bei komplexeren Arbeiten wird die Entwicklung von Code im Browser als Notebook jedoch anstrengend und ineffizient. Je länger das Notebook, desto schwieriger ist der Code zu lesen, und die Umgebung reagiert weniger schnell, wenn man “Autocomplete” nutzt oder Zellen hinzufügt. Glücklicherweise können wir Code direkt aus der lokalen IDE schreiben und ausführen. In diesem Artikel zeigen wir Schritt für Schritt, wie man sich mit einem Databricks Cluster verbindet und Spark-Code mit dem “databricks connector” ausführt.
Implementierung
Stelle die Effizienz deiner Arbeit sicher, indem du deine Entwicklungsumgebung richtig vorbereitest – das ist entscheidend, um erfolgreich eine Verbindung zu einem Databricks Cluster aus der lokalen IDE herzustellen.
Vorbereitung der Umgebung
Die passende Python-Version in deiner Entwicklungsumgebung ist erforderlich, um dich mit deinem Cluster in Databricks zu verbinden. Zum Beispiel: Wenn du dich mit einem Cluster mit Databricks Runtime 7.3 LTS verbindest, musst du Python Version 3.7 verwenden. Es ist wichtig zu erwähnen, dass nicht alle DB Runtimes unterstützt werden (Einschränkungen werden später im Artikel beschrieben). Eine vollständige Liste der unterstützten Runtimes und der entsprechenden Python-Versionen findest du hier.
Außerdem muss Java Runtime Environment 8 (JRE 8) installiert sein. Unter Ubuntu/Debian kannst du apt zur Installation verwenden.
Das Paket databricks-connect steht im Konflikt mit PySpark. Wenn dein Python-Environment PySpark enthält, entferne es mit folgendem Befehl.
Es wird außerdem empfohlen, ein sauberes Python-Environment mit venv, conda oder anderen Tools zu verwenden. So kannst du Verbindungen zu mehreren Clustern/Workspaces von einem Ort aus konfigurieren.
Verbindung zum Cluster
Wie verbindet man sich mit einem Databricks Cluster? Sobald die lokale Umgebung bereit ist, installiere das Paket databricks-connect. Die Client-Version sollte mit der Databricks Runtime übereinstimmen. In unserem Fall ist das 7.3:

Beachte, dass die Client-Version “X.Y.” ist, wobei X.Y der Databricks Runtime (7.3) entspricht und “” die Paketversion ist. Mit “*” nutzt du immer die neueste Version.
Nach erfolgreicher Installation ist es Zeit, die Verbindung zu konfigurieren. Dafür benötigst du:
- Workspace url (Databricks host)
- Cluster ID
- Organization ID (Org ID) (nur Azure!)
- Personal token
- Connection port
Die ersten drei Parameter findest du in der URL des Clusters, mit dem du dich verbinden möchtest. Öffne in deinem Browser “Compute” und dann den gewünschten Cluster. Einen Personal Token kannst du in den “User settings” generieren. Wie das geht, findest du hier.
Der Standard-Port ist 15001. Falls er geändert wurde, findest du ihn wahrscheinlich unter “Advanced Options” im Tab “Spark” (Konfigurationsschlüssel “spark.databricks.service.port”).
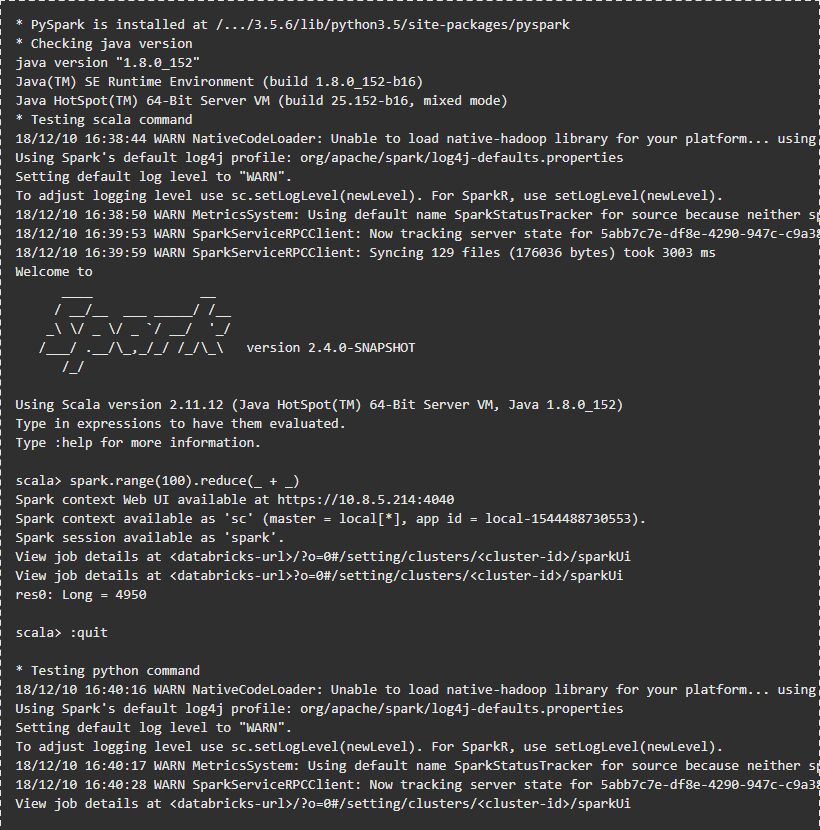
Wenn alle erforderlichen Parameter bereit sind, kannst du den databricks connection client konfigurieren:
Gib die abgefragten Parameter ein. Danach kannst du die Verbindung testen:
Die Ausgabe sollte so aussehen:
Beispielcode ausführen
Integration mit VSC IDE
Bevor du Code auf einem Databricks Cluster ausführst, musst du den databricks-connector mit deiner IDE integrieren. In meinem Fall ist das Visual Studio Code. Die Integration mit VSC ist sehr einfach – du musst nur das Python-Environment auswählen, in dem der databricks-connector installiert ist. Wenn du PySpark-Code ausführst, wird der Connector ihn auf dem DB Cluster ausführen.
Um den Python-Interpreter in VSC zu ändern, drücke F1 und beginne mit der Eingabe von “Python: Select Interpreter”.

Wähle dann das Python-Environment aus der Liste oder gib den Pfad zur Python-Executable an.
Jetzt kannst du deinen Code aus der IDE auf dem DB Cluster ausführen. Der databricks connector erkennt pyspark-Code und führt ihn auf dem Cluster aus. Wenn der Code kein pyspark enthält, wird er lokal ausgeführt. Unten siehst du ein Beispiel mit pyspark, das auf dem DB Cluster ausgeführt wird.
Beachte, dass zuerst eine spark session erstellt werden muss. Wenn du Code direkt im Databricks Workspace ausführst, ist die spark session bereits initialisiert. Den Code findest du in diesem Repository.
Nicht nur VSC!
Du kannst viele IDEs integrieren, z. B. PyCharm, Eclipse oder Jupyter Notebook. Anleitungen zur Konfiguration anderer IDEs findest du hier.
Zugriff auf DBUtils
DBUtils ist ein sehr hilfreiches Modul für die Arbeit mit Notebooks. Damit kannst du Secrets lesen oder FS-Befehle auf DBFS ausführen. Du kannst “dbutils” genauso verwenden wie in Databricks Notebooks.
Dafür musst du das Paket “six” installieren:
Jetzt kannst du fs und secrets verwenden:
Das Beispiel findest du im Repository.
Zugriff auf Code aus dem DB Workspace
Du kannst Notebooks mit der databricks CLI aus dem DB Workspace herunterladen und hochladen. Um die CLI zu installieren, führe im Terminal aus:
Um die databricks CLI zu konfigurieren, benötigst du die Workspace-URL und den Token. Wie du sie bekommst, habe ich oben beschrieben. Beide müssen bei der Konfiguration angegeben werden:
Verwende dann die Import- und Export-Befehle:
Mit der Databricks CLI kannst du auch Cluster erstellen, dbfs verwalten usw. Eine vollständige Liste der Befehle findest du hier.
Nicht nur Py!
Du kannst deine Umgebung und IDE auch für R-Code und Scala konfigurieren!
Weitere Informationen findest du unter folgenden Links:
- R code -> Link
- Scala/Java -> Link
Einschränkungen
Leider gibt es einige Einschränkungen bei der Nutzung des databricks-connector. Erstens können nur bestimmte DB Runtime clusters verwendet werden. Zum Zeitpunkt des Artikels waren das: 9.1 LTS, 7.3 LTS, 6.4 und 5.5 LTS. Nur die Module fs und secrets aus dbutils sind verfügbar. Die Module library, notebook oder widgets werden vom databricks-connector nicht unterstützt. Außerdem ist es nicht möglich, sich mit Clustern mit Table access control zu verbinden.
Das sind die wichtigsten Einschränkungen. Die vollständige Liste findest du hier:
- Azure
- AWS
- GCP
Zusammenfassung
Wie du siehst, ist das Einrichten des “databricks connect” Pakets einfach und beschleunigt die Entwicklung in deiner Lieblings-IDE erheblich. Den gesamten Code findest du in einem speziell erstellten GitHub-Repository. Schau auf unserem Blog vorbei, um mehr über Databricks Clusters zu erfahren.
Data pipeline definition design und prozess




